|
Topics to be learn in in Part-1
- The Discovery of DNA
- The Genetic Material is a DNA
- DNA packaging
- DNA replication
- Protein synthesis
Topics to be learn in Part-2 :
- Protein synthesis
- Regulation of gene expression
- Operon concept
- Genomics
- Human Genome Project
- DNA Fingerprinting
|
Protein Synthesis : Proteins are very important biomolecules. They serve as structural components, enzymes and hormones. The cell needs to synsthesize new protein molecules. The process of protein synthesis includes transcription and translation.
Central dogma : Central dogma of molecular biology was postulated by F.H.C. Crick in 1958.
DNA- \( \underrightarrow{Transcription}\) -mRNA- \(\underrightarrow{Translation}\) - Polypeptide
- DNA gets transcribe to form m-RNA, m-RNA acts as a messenger and gets translated to form a polypeptide chain (protein) having specific amino acid sequence.
- This unidirectional flow of information from DNA to RNA and from RNA to proteins is referred as central dogma of molecular biology
- Temin (1970) and Baltimore (1970) : Central dogma in retroviruses.

Transcription : Transcription is the process of copying of genetic information from one (template) strand of DNA into a complementary single stranded RNA transcript. Occurs in the nucleus during G1 and G2 phases of cell cycle.
Catalyzed by RNA polymerase :
(i) Prokaryotes : One type of RNA polymerase.
(ii) Eukaryotes :
- RNA polymerase-I : Transcription of r-RNA.
- RNA polymerase-II : Transcription of m-RNA and heterogeneous nuclear-
- RNA (or hnRNA). -
- RNA polymerase-III : Transcription of t-RNA and small nuclear-RNA (snRNA).
Transcription Unit :
Transcription Unit : Transcription unit (Each transcribed segment of DNA) consists of the promoter, the structural gene and the terminator.

(i) The promoter :
- Located towards 5’ end of structural gene, i.e. upstream.
- Provides binding site for enzyme RNA polymerase.
- In prokaryotes, sigma factor sub unit of the enzyme recognizes the promoter.
(ii) Structural genes :
- Template strand (Antisense strand) : DNA strand having 3’—>5' polarity acts as template strand as DNA dependent RNA polymerase catalyses polymerization in 5’—>3’ direction.
- Sense strand : The other strand of DNA having 5’—>3’ polarity is complementary to template strand. It is called as sense strand. The sequence of bases in this strand, is same as in RNA (where Thymine is replaced by Uracil). It is the actual coding strand.
(iii) The terminator :
- Located at 3’ end of coding strand, i.e. downstream.
- Defines the end of the transcription process.
[collapse]
Three stages of transcription :
Three stages of transcription :
Prokaryotes and Eukaryotes, involves three stages of transcription viz. Initiation, Elongation and Termination.
(1) Initiation :
- RNA polymerase binds to promoter site.
- It then moves along the DNA and causeslocal unwinding of DNA duplex into two strands in the region of the gene.
- Only antisense strand functions as template.
(2) Elongation :
- The complementary ribonucleoside tri-phosphates get attached to exposed bases of DNA template chain.
- As transcription proceeds, the hybrid DNA-RNA molecule dissociates and makes m-RNA molecule free.
- As the m-RNA grows, the transcribed region of DNA molecule becomes spirally coiled and regains double helical form
(3) Termination : When RNA polymerase reaches the terminator site on the DNA, both enzyme and newly formed m-RNA (primary transcript) gets released.
[collapse]
Transcription unit and the gene :
Transcription unit and the gene :
Gene : The DNA sequence coding for m-RNA/t-RNA or r-RNA.
Cistron : A segment of DNA coding for a polypeptide.
Monocistronic gene : A single structural gene in transcription unit.
Polycistronic gene : One transcription unit having a set of various structural genes.
Interrupted genes (Split genes) : Structural genes with both exons and introns).
- Exons : The coding sequences or express sequences.
- Introns : The non-coding sequences.
- Only exons appear in processed m-RNA in eukaryotes.
In bacteria, m-RNA does not require any processing because it has no introns.
[collapse]
Processing of hnRNA :
Processing of hnRNA :
- Eukaryotes have split genes.
- Primary transcript or hnRNA is non-functional and contains both exons and introns.
- Processing of hnRNA results in functional m-RNA.
- hnRNA undergoes capping, tailing and splicing.
- Capping: Methylated guanosine tri-phosphate is added to 5‘ end of hnRNA.
- Tailing : Polyadenylation take place at 3’ end.
- Splicing : It is removal of introns.

- DNA ligase joins exons in a definite sequence (order).
- The fully processed hnRNA is called m-RNA.
- m-RNA comes out of the nucleus through nuclear pore for getting translated.
[collapse]
Genetic Code: About, 20 different types of amino acids are involved in the process of synthesis of proteins. DNA molecule has 4 types of nitrogen bases to identify these 20 different types of amino acids. Question arises then, how is it possible that 20 types of amino acids are encoded by 4 types of nitrogen bases?
- Yanofski and Sarabhai (1964) : Provided evidence that DNA carries the information for the protein synthesis as the sequence of nucleotides.
- F.H.C. Crick : According to Crick the information for protein synthesis is stored in the form of coded language (cryptogram) called genetic code. He gave evidence for the triplet nature of genetic code, by using “frame-shift mutation”.
- G. Gamow (1954) : Suggested that codon is a sequence of three consecutive nucleotides on m-RNA.
Cracking of genetic code :
Cracking of genetic code :
- M. Nirenberg and Matthaei synthesized artificial poly-U m-RNA.
- Using this synthetic poly-U m-RNA and cell free system of protein synthesis, a small polypeptide consisting of only amino acid phenylalanine was obtained.
- It suggested that UUU codes for phenylalanine
- Dr. Har Gobind Khorana devised a technique for synthesis of artificial m-RNA with repeated sequences of known nucleotides
- He synthesized artificial RNA consisting of known repeated sequences of two or three nucleotides. E.g. CUC, UCU, CUC, UCU by using synthetic DNA.
- This resulted in formation of polypeptide chain consisting of alternate amino acids leucine and serine.
- Synthetic RNA consisting of CUA, CUA, CUA, CUA repeats gave polypeptide chain with only one amino acid - leucine.
- Severo Ochoa established that the enzyme(polynucleotide phosphorylase) also helps in polymerizing RNA of defined sequences in a template-independent manner (i.e. enzymatic synthesis of RNA).
- Thus all the 64 codons in the dictionary of genetic code were deciphered.
[collapse]
Characteristics of Genetic code :
Characteristics of Genetic code ; Genetic code of DNA has certain fundamental characteristics –
- Genetic code is a triplet code : Sequence of three consecutive bases constitute codon, which specifies one particular amino acid.
- Genetic code has distinct polarity : Genetic code is always read in 5’ —> 3’ direction.
- Genetic code is Non-overlapping code : Each single nucleotide is a part of only one codon.
- Genetic code is Commaless : There is no gap between successive codons.
- Genetic code has Degeneracy : Two or more codons can specify the same amino acid. E.g. Cysteine has two codons, while isoleucin has three codons. Degeneracy of the code is explained by Wobble hypothesis.
- Genetic code is universal : By and large in all living organisms the specific codon specifies same amino acid. e.g. codon AUG always specifies amino acid methionine in all organisms from bacteria up to humans.
- Genetic code is Non-ambiguous code : Each codon specifies a particular amino acid.
- Initiation codon : AUG, Codes for amino acid methionine.
- Termination codons : UAA, UAG and UGA : They do not code for any amino acid. They stop the process of elongation of polypeptide chain.
- Codon : A triplet of nucleotides present on DNA that codes for specific amino acid. E.g. AUG is codon.
- Anticodon : Triplet of nucleotides present on the anticodon loop of t-RNA, which is complementary to codon on m-RNA,
- Wobble hypothesis : In codon-anticodon pairing the third base may not be complementary.
[collapse]
Mutations and Genetic Code:
Mutation is a phenomenon in which sudden change in the DNA sequence takes place. It results in the change of genotype (i.e. character).
Mutation and recombination : Mutation and recombination is raw material for evolution as it generates variations.
Types of mutations :
Types of mutations :
- Chromosomal mutations : Loss (deletion) or gain (insertion/duplication) of a segment of DNA results in alteration in the chromosome.
- Point mutations : Involve change in a single base pair of DNA. E.g. mutation that results in Sickle-cell anaemia.
- Deletion or insertion of base pairs of DNA : It causes frame-shift mutations or deletion mutation.
- Insertion or deletion of one or two bases changes the reading frame from the point of insertion or deletion.
- Insertion or deletion of three or multiples of three bases [insert or delete) results in insertion or deletion of amino acids and reading frame remains unaltered from that point onwards.
[collapse]
Transfer-RNA (t-RNA) :
Transfer-RNA (t-RNA): As t-RNA can read the codon and also can bind with the amino acid, t-RNA is considered as an adapter molecule.
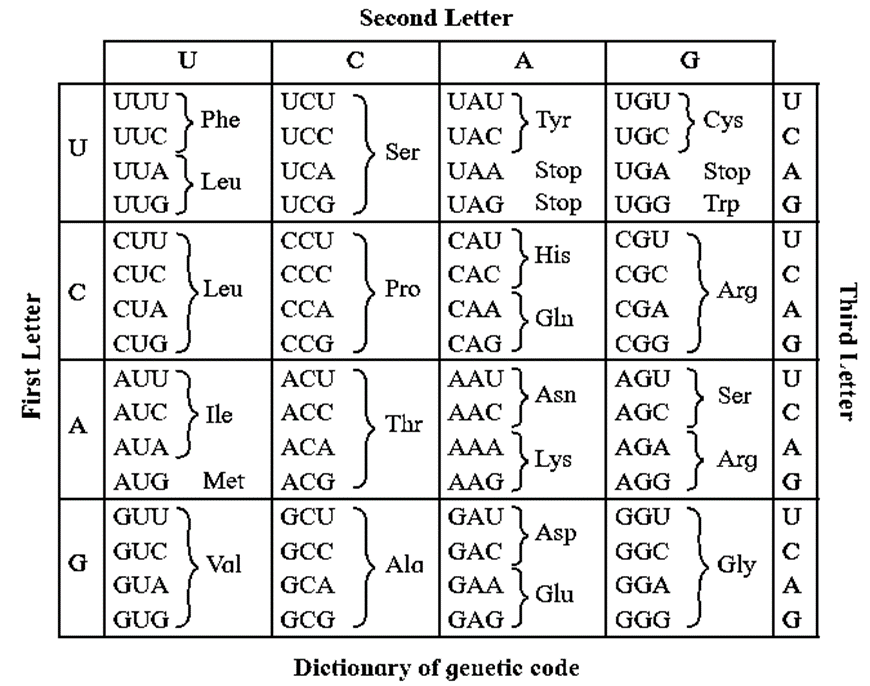
Clover leaf structure (2 dimensional) of t-RNA :
- t-RNA has four arms—DHU arm (has amino acyl binding loop), middle arm (has anticodon loop), T y C arm (has ribosome binding loop) and variable arm.
- It has G nucleotide at 5’ end.
- Amino acid acceptor end (3’ end) having unpaired CCA bases (i.e. amino acid binding site).
For every amino acid, there is specific t-RNA. Initiator t-RNA is specific for methionine. There are no t-RNAs for stop codons.
In the actual structure, the t-RNA molecule looks like inverted L (3 dimensional structure).
[collapse]
Translation — protein synthesis : Translation is the process in which sequence of codons on m-RNA is decoded and accordingly amino acids are added in specific sequence to form a polypeptide on ribosomes.
It requires 20 different amino acids, m-RNA, t-RNA, ribosomes, ATP, Mg++ ions, enzymes, elongation, translocation and release factors.

Translation involves three steps : i. Initiation, ii. Elongation, iii. Termination
Activation of amino acids is essential before translation initiates for which ATP is essential.
- In the presence of an enzyme amino acyl t-RNA synthetase, the amino acid is activated and then attached to the specific t-RNA molecule at 3’ end to form charged t-RNA (t-RNA - amino acid complex).
- ATP is essential for the reaction.
Three steps of Translation :
(i) Initiation of Polypeptide chain :
- Small subunit of ribosome binds to the m-RNA at 5’ end.
- Start codon is positioned properly at P-site.
- Initiator t-RNA, (carrying amino acid methionine in eukaryotes or formyl methionine in prokaryotes) binds with initiation codon (AUG) of m-RNA, by its anticodon (UAC) through hydrogen bonds.
- The large subunit of ribosome joins with the smaller subunit in the presence of Mg++.
- Thus, initiator charged t-RNA occupies the P-site and A-site is vacant.
(ii) Elongations of polypeptide chain : Addition of amino acid occurs in 3 Step cycle
(a) Codon recognition :
- Anticodon of second (and subsequent) amino acyl t-RNA molecule recognizes and binds with codon at A-site by hydrogen bonds.
(b) Peptide bond formation :
- Ribozyme catalyzes the peptide bond formation between amino acids on the initiator t-RNA at P-site and t-RNA at A-site.
- It takes less than 0.1 second for formation of peptide bond.
- 0 Initiator t-RNA at ‘P’ site is then released from E-site.
(c) Translocation :
- Translocation is the process in which sequence of codons on m-RNA is decoded and accordingly amino acids are added in specific sequence to form a polypeptide on ribosomes.
- Due to this ‘A’-site becomes vacant to receive next charged t-RNA molecule.
- The events like arrival of t-RNA – amino acid complex, formation of peptide bond, ribosomal translocation and release of previous t-RNA, are repeated.
- As ribosome move over the m-RNA, all the codons on m-RNA are exposed one by one for translation.
(iii) Termination and release of polypeptide :
- When stop codon (UAA, UAG, UGA) gets exposed at the A-site, the release factor binds to the stop codon, thereby terminating the translation process.
- The polypeptide gets released in the cytoplasm.
- Two subunits of ribosome “dissociate and last t-RNA and m-RNA are released in the cytoplasm.
- m-RNA gets denatured by nucleases immediately.
[collapse]
Regulation of gene expression :
Regulation of gene expression: It is the multistep process by which a gene is regulated and its product is synthesized.
In eukaryotes, the regulation can be at different levels like-
- Transcriptional level (formation of primary transcript)
- Processing level (regulation of splicing)
- Transport of m-RNA from nucleus to the cytoplasm.
- Translational level.
[collapse]
Operon concept : A transcriptional control mechanism of gene regulation.
Francois Jacob and Jacques Monod (1961) : Explained that metabolic pathways are regulated as a unit.
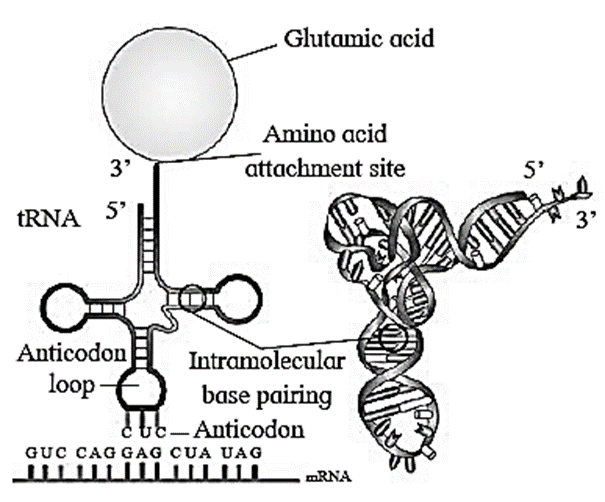
Lac operon of E. coli :
- An inducible operon.
- The operon is switched on by a chemical inducer-lactose present in the medium.
Components of Lac operon :
Lac operon consists of the following components :
(i) Regulator gene :
- Regulator gene precedes the promoter gene.
- It may not be present immediately adjacent to operator gene.
- Regulator gene codes for a repressor protein which binds with operator gene and represses (stops) its action.
(ii) Promoter gene :
- It precedes the operator gene.
- It is present adjacent to operator gene.
- RNA Polymerase enzyme binds at promoter site.
Promoter gene base sequence determines which strand of DNA acts a template.
(iii) Operator gene :
- It precedes the structural genes.
- When operator gene is turned on by an inducer, the structural genes get transcribed to form m-RNA.
(iv) Structural gene :
- There are 3 structural genes in The sequence lac-Z, lac-Y and lac-A.
- Enzymes produced are b-galactosidase, b-galactoside permease and transacetylase respectively.
Inducer: Allolactose acts as an inducer. It inactivates the repressor by binding with it. (Inducer is a not a component of operon).
[collapse]
Genomics: The term Genome (introduced by H.Winkler in 1920).
- Genome : The total genetic constitution of an organism or a complete copy of genetic information (DNA) or one complete set of chromosomes (monoploid or haploid) of an organism.
- Genomics (term coined by T.H. Roderick in 1986) : The study of genomes through analysis, sequencing and mapping of genes along with the study of their functions.
Two types of Genomics :
- Structural genomics : Involves mapping sequencing and analysis of genome.
- Functional genomics : Involves the study of functions of all gene sequences and their expressions in organisms.
Application of genomics :
Application of genomics :
- Structural and functional genomics are used in the improvement of crop plant, human health and livestock.
- The knowledge and understanding acquired by genomics research can be applied in medicine, biotechnology and social sciences.
- It helps in the treatment of genetic disorders through gene therapy.
- To develop transgenic crops having more desirable characters.
- Genetic markers have applications in forensic analysis.
- Genomics can lead to introduce new gene in microbes to produce enzymes, therapeutic proteins and even biofuels.
[collapse]
Human Genome Project (HGP) :
- Initiated in 1990 under the International administration of the Human Genome Organization (HUGO).
- Coordinated by the US Department of Energy and National Institute of Health, some universities across the United States and various international partners.
- Started in 1990 and completed in 2003.
Aims of HGP :
Aims of HGP :
- Mapping the entire human genome at the level of nucleotide sequences.
- To store the information collected from the project in databases.
- To develop tools and techniques for analysis of the data.
- Transfer of the related technologies to the private sectors, such as industries.
- Taking care of the legal, ethical and social issues which may arise from project.
- To provide complete and accurate sequence of the 3 billion DNA base pairs that make up the human genome.
- To find out the estimated number of human genes. Now about 33,000 genes have been estimated to be present in humans.
- To sequence the genomes of several other organisms such as bacteria e.g. E.coli, Caenorhabditis elegans, Saccharomyces cerevisiae, Drosophil, rice, Arabidopsis), Mus musculus etc.
HGP was closely associated with rapid development of Bioinformatics.
[collapse]
Significance of HGP :
Significance :
- Increased knowledge about the functions of genes and proteins.
- A major impact in the fields like Medicine.
- Biotechnology and the Life sciences.
- Increased understanding of gene structure and function in other species, such studies will enhance understanding of human evolution.
[collapse]
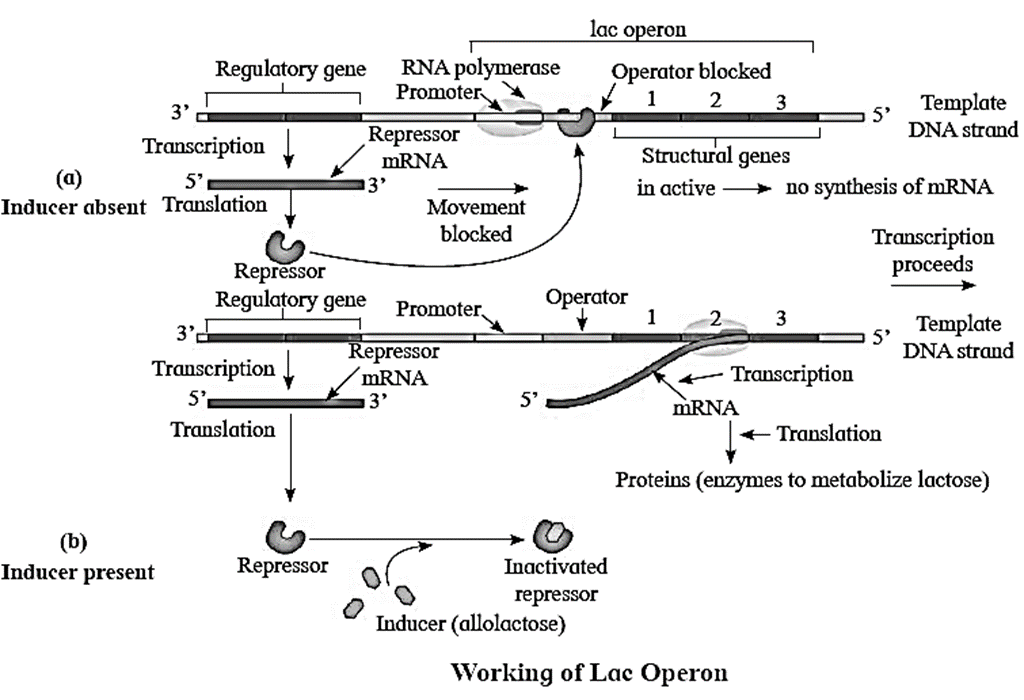
Comparative genome sizes of humans and other models organisms :
Comparative genome sizes of humans and other models organisms.
[collapse]
| Q. What have we learnt from the Human Genome Project?
SAnswer :
- We have learnt following salient features of human genome from the Human Genome Project.
- The human genome contains 3164.7 million nucleotide bases.
- The average gene consists of 3000 bases.
- Largest known human gene is dystrophin at 2.4 million bases.
- Total number of genes is estimated to be 3000.
- 99.9% nucleotide bases are exactly the same in all people.
- The function of about 50% of the discovered genes are unknown.
- Less than 2% of the genome codes for proteins.
- Repeated sequences make up a very large portion of the human genome. They can shed light on chromosome structure, dynamics and evolution.
- Chromosome 1 has most genes (2968) and the Y has the fewest (231).
- Single nucleotide polymorphism have been identified at about 1.4 million locations. It is useful in finding chromosomal locations for disease-associated sequences and tracing human history.
[collapse]
|
DNA Fingerprinting : Every individual has its unique genetic make-up, called its Fingerprint.
Reasons for Uniqueness of fingerprint :
- Recombination of paternal and maternal genes, because of which we differ from our parents.
- Infrequent mutations that occur during gamete formation (cell division).
The DNA profiling or DNA fingerprinting technique (developed by Dr. Alec Jeffreys in
1984) identifies a person with the help of DNA restriction analysis.
It is based on identification of nucleotide sequence present in DNA.
- About 99.9% of nucleotide sequence in all persons, is same.
- Variable Number of Tandem Repeats [VNTRs] : Unusual sequences of 20 — 100 base pairs, which are repeated several times.
- As the length of the regions having VNTRs is different in each individual, they are the key factor in DNA profiling.
Steps involved in DNA finger printing :
Steps involved in DNA finger printing :
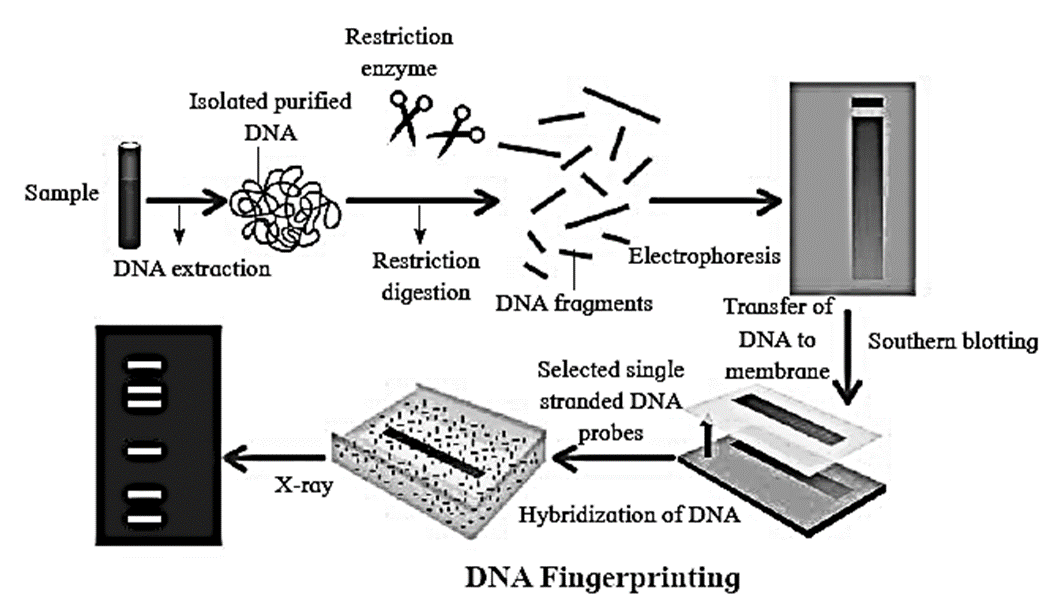
(i) Isolation of DNA : The DNA can be isolated even from the small amount of tissue like blood, hair roots, skin, etc.
(ii) Restriction digestion :
- The isolated DNA is treated with restriction enzymes which cut the DNA at specific sites to form small fragments of variable lengths.
- Variations in the lengths of restriction fragments are known as Restriction Fragment Length Polymorphism (RFLP).
(iii) Gel electrophoresis :
- The DNA samples are loaded on agarose gel and electrophoresis is carried out.
- Negatively charged DNA fragments move to the positive pole.
- Separation of fragments depends on their length and it results in formation of bands.
- dsDNA is then denatured into ssDNA by alkali treatment.
(iv) Southern blotting : The separated DNA fragments are transferred to a nylon membrane or a nitrocellulose membrane.
(v) Selection of DNA probe :
- DNA Probe is a known sequence of single-stranded DNA.
- It is obtained from organisms or prepared by cDNA preparation method.
- The DNA probe is labelled with radioactive isotopes.
(vi) Hybridization :
- In this process, probe is added to the nitrocellulose membrane containing DNA fragments.
- The single-stranded DNA probe pairs with the complementary base sequence of the
- DNA strand.
- As a result DNA-DNA hybrids are formed on the nitrocellulose membrane. Unbound single-stranded DNA probe fragments are washed off.
(vii) Photography : The nitrocellulose membrane is then kept in contact with X-ray film. DNA bands, due to radioactive probe, give photographic image on X-ray film. This is autoradiography.
[collapse]
Application of DNA fingerprinting :
- Used in forensic sciences to solve rape and murder cases.
- Finds out the biological father or mother or both, of the child, in case of disputed parentage.
- Used in pedigree analysis in cats, dogs, horses and humans.
Scientist - Dr. Lalji Singh :
Scientist - Dr. Lalji Singh ( 1947 - 2017):
Father of DNA fingerprinting in India.
A unique segment obtained from Y chromosome of female banded krait snake (banded krait minor — BKM-DNA) was used by him to develop probe for DNA fingerprinting.
His contributions :
- Established laboratories for research in fields like genetics, population biology, structural biology and transgenics.
- Established centre for DNA Fingerprinting and Diagnostics (CDFD) for all species and several diseases.
- Founded laboratory for Conservation of Endangered Species (LaCONES).
- Applied of DNA fingerprinting technology for Wildlife conservation, forensics, evolution and phylogenetic research.
[collapse]
<<-Previous Part
We reply to valid query.