Notes-Part-2
Topics to be Learn : Part-2
|
Proteins :
- Proteins are the fundamental structural materials of animal bodies. Proteins in the form of enzymes play prime role in all the physiological reactions.
- Chemically proteins are polyamides which are high molecular weight polymers of the monomer units i.e. ∝-amino
- OR It can also be defined as proteins are the biopolymers of a large number of ∝-amino acids and they are naturally occurring polymeric nitrogenous organic compounds containing 16% nitrogen and peptide linkages (-CO-NH-).
Common sources of proteins : Common sources of proteins are milk, pulses, peanuts, eggs, fishes, cheese, cereals, etc. They are also the principal materials of muscle, nerves, tendons, skin, blood, enzymes, many hormones and antibiotics.
Products of hydrolysis of proteins : On hydrolysis, proteins give a mixture of ∝-amino acids.

The ∝-carbon in ∝-amino acids obtained by hydrolysis of proteins has ‘L’ configuration.
∝-Amino acids : ∝-Amino acids are carboxylic acids having an amino (-NH2) group bonded to the ∝-carbon, i.e. the carbon next to the carboxyl (—COOH) group.
∝-amino acids are derivatives of carboxylic acids, obtained by replacing ∝—H atom by amino group. They are bifunctional compounds containing acidic (-COOH) and basic –NH2 groups.

Example :
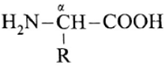
(where R is an alkyl group or aryl group).
The amino acids are colourless, crystalline, water soluble, high melting solids. These acids in their aqueons solutions behave like salts due to presence of both acidic, (-COOH) and basic –NH2 groups in the same molecule. Such a doubly charged ion is known as zwitter ion.

Zwitter ion : An ∝-amino acid molecule contains both acidic carboxyl (-COOH) group as well as basic amino (-NH2) group. Proton transfer from acidic group to basic group of amino acid forms a salt, which is a dipolar ion called zwitter ion.

Zwitter ion of alanine and other two forms :

Final products of hydrolysis of proteins :
Proteins on hydrolysis with dilute solution of acids, alkalies or enzymes give a mixture of large number of ∝-amino acids as final products.
For example,

Classification of amino acids :
The amino acids are of three types : acidic, basic and neutral. The symbol ‘R’ in the structure of ∝-amino acids represents side chain and may contain additional functional groups.
(i) Acidic amino acids : If ‘R’ contains a carboxyl (—COOH) group the amino acid is acidic amino acid. i.e. If carboxyl groups are more in number than amino groups, then amino acids are acidic in nature.
Examples : Glutamic acid HOOC-CH2-CH2—; Aspartic acid HOOC—CH2—
(ii) Basic amino acids : If ‘R’ contains an amino (1°, 2°, or 3°) group, it is called basic amino acid i.e. If amino groups are more in number than carboxyl groups then amino acids are basic in nature.
Examples :

(iii) Neutral amino acids : The other amino acids having neutral or no functional group in ‘R’ are called neutral amino acids. i.e. The amino acids having equal number of amino and carboxyl groups are neutral amino acids.
Examples : Alanine CH3—; Valine (CH3)2—CH
Essential and non-essential amino acids :
The amino acids, which cannot be synthesised in the body and are supplied through diet are called essential amino acids.
- Examples : Lysine H2N—(CH2)4—; Valine (CH3)2CH—
The amino acids which are synthesized in the body are called non-essential amino acids.
- Examples : Glutamic acid HOOC— CH2— CH2— ; Serine HO—CH2—
| Know This :
At the physiological pH of 7.4, neutral ∝-amino acids are primarily in their zwitterionic forms. On the other hand, at this pH acidic ∝-amino acids exist as anion (due to deprotonation of the carboxyl group), while basic ∝-amino acids exist as cation (due to protonation of the amino groups). Ionic structures of constituent ∝-amino acids result in ionic nature of proteins. |
Peptide bond and protein :
Peptide bond : Proteins are the polymers of ∝-amino acids and they are connected to each other. The bond that connects ∝-amino acids to each other is called peptide bond (peptide linkage, —CONH—).
Formation of peptide linkage :
Peptide linkage is formed by condensation of acidic (-COOH) group of one molecule of ∝-amino acid and basic —NH2 group of other molecule of a-amino acid with elimination of water.

When one more molecule of amino acid combines with dipeptide, it forms tripeptide.
Tripeptide :

Thus, it forms tetra, penta and finally a polypeptide chain i.e. proteins. Hence, proteins are basically polypeptides.
Schematic representations of all the possible dipeptides :
(i) Dipeptide from glycine :
Carboxylic group of glycine reacting with amino group another molecule of glycine to form dipeptide
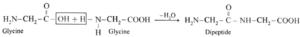
(ii) Dipeptide from alanine :
Carboxylic group of alanine reacting with amino group of another molecule of alamine to form dipeptide.
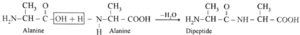
(iii) Dipeptide from glycine and alanine :
Carboxylic group of glycine reacting with amino group another molecule of alanine to form dipeptide
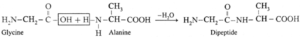
(iv) Dipeptide formed from alanine and tyrosine :

(v) Dipeptide formed from glycine and tyrosine :

Types of proteins :
Depending upon the molecular shape proteins are classified into two types.
(i) Fibrous proteins : The proteins in which the polypeptide chains lie parallel (side by side) to form fibre-like structure, are called fibrous proteins.
- The polypeptide chains held together by hydrogen bonds and disulphide bonds.
- These proteins are insoluble in water.
- The fibrous proteins are tough and insoluble in water, and dilute acids or bases.
- They are stable to moderate changes of temperature and pH.
- They do not possess biological activity.
Examples : myocin (in muscles), keratin (in hair, nails, skin), fibroin (in silk), collagen (in tendons), etc.
(ii) Globular proteins : The proteins have spherical shape. This shape results from coiling around of the polypeptide chain of protein, and have intramolecular hydrogen bonding are called globular proteins.
- They are soluble in water and dilute acids or bases.
- They are sensitive to small changes of temperature and pH
- They possess biological activity.
Examples : Haemoglobin (in blood), albumin (in eggs), insulin (in pancreas), etc.
Structure of proteins :
- Proteins are responsible for a variety of functions in organisms.
- Proteins of hair, muscles, skin give shape to the structure, while enzymes are proteins which catalyze physiological reactions.
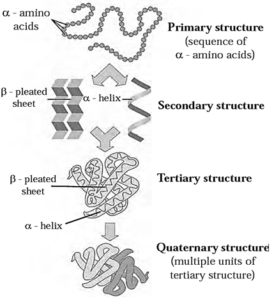
These diverse functions of proteins can be understood by studying the four level structure of proteins, namely primary, secondary, tertiary and quaternary structure of proteins. Each level is more complex than the previous one.
(i) Primary structure of proteins :
(a) Representation by structural formula

(b) Representation with amino acid symbols

- Primary structure of proteins is the sequence of constituent ¢-amino acid residues linked by peptide bonds.
- Any change in the sequence of amino acid residue creates different protein molecule. Primary structure of proteins is represented by writing the three letter symbols of amino acid residues as per their sequence in the concerned protein. The symbols are separated by dashes.
- According to the convention, the N-terminal amino acid residue as written at the left end and the C-terminal amino acid residue at the right end.
Secondary structure of proteins : The three-dimensional arrangement of localized regions of a long polypeptide chain is called the secondary structure of protein.
Hydrogen bonding between N-H proton of one amide linkage and C = O oxygen of another gives rise to the secondary structure.
There are two different types of secondary structures i.e. ∝-helix and β-pleated sheet.
(i) ∝-Helix : In ∝-helix structure, a polypeptide chain gets coiled by twisting into a right handed or clockwise spiral known as ∝-helix. The characteristic features of ∝-helical
structure of protein are :
- Each turn of the helix has 3.6 amino acids.
- A C = O group of one amino acid is hydrogen bonded to N—H group of the fourth amino acid along the chain.
- Hydrogen bonds are parallel to the axis of helix while groups extend outward from the helix core.
Myosin in muscle and ∝-keratin in hair are proteins with almost entire ∝-helical secondary structure.

(ii) β-Pleated sheet : The secondary structure is called β-pleated sheet when two or more polypeptide chains, called strands, line up side-by-side (Fig.)

The β-pleated sheet structure of protein consists of extended strands of polypeptide chains held together by hydrogen bonding. The characteristics of β-pleated sheet structure are :
- The C=O and N-H bonds lie in the planes of the sheet.
- Hydrogen bonding occurs between the N-H and C=O groups of nearby amino acid residues in the neighbouring chains.
- The R groups are oriented above and below the plane of the sheet.
The β-pleated sheet arrangement is favoured by amino acids with small R groups.
(iii) Tertiary structure of proteins : The three-dimensional shape adopted by the entire polypeptide chain of a protein is called its tertiary structure.
It is the result of folding of the chain in a particular manner that the structure is itself stabilized and also has attractive interaction with the aqueous environment of the cell.
- The globular and fibrous proteins represent two major molecular shapes resulting from the tertiary structure.
- The forces that stabilize a particular tertiary structure include hydrogen bonding, dipoledipole attraction (due to polar bonds in the side chains), electrostatic attraction (due to the ionic groups like -COO , NH3+ in the side chain) and also London dispersion forces.
- Finally, disulfide bonds formed by oxidation of nearby -SH groups (in cysteine residues) are the covalent bonds which stabilize the tertiary structure (Fig.).

(iv) Quaternary structure of proteins : The two or more polypeptide chains with folded tertiary structures forms complex protein. The spatial arrangements of these
polypeptide chains with respect to each other is known as quaternary structure.
Each individual polypeptide chain is called a subunit of the overall protein.
For example: Haemoglobin consists of four subunits called haeme held together by intermolecular forces in a compact three dimensional shape.
Haemoglobin can do its function of oxygen transport only when all the four subunits are together.
Fig : Summary of four levels of protein structure :
Denaturation of proteins :
The process by which the molecular shape of protein changes without breaking the amide / peptide bonds that form the primary structure is called denaturation. OR Proteins gets easily precipitated. It is an irreversible change and the process is called denaturation of proteins.
- Denaturation uncoils the protein and destroys the shape and thus loses their characteristic biological activity.
- Denaturation is brought about by heating the protein with alcohol, concentrated inorganic acids or by salts of heavy metals.
- During denaturation secondary and tertiary and quternary structures are destroyed but primary structure remains intact.
Example : Boiling of egg to coagulate egg white, conversion of milk to curd.
- When egg is boiled, coagulation of eggwhite (insoluble fibrous proteins) takes place. This is a common example of denaturation.
- When lemon juice is added to milk, it gets curdled due to the formation of lactic acid. This is another example of denaturation.
| Know This :
Globular proteins are typically folded with hydrophobic side chains in the interior and polar residues on the outside, and thereby are water soluble. Denaturation exposes the hydrophobic region of globular proteins and makes them water soluble |
Enzymes :
All biological reactions are brought about at the physiological pH of 7.4 and the body temperature of 37 °C with the help of biological catalysts called enzymes. Chemically all enzymes are proteins.
Functions :
- They are required in very small quantities as they are catalyst also they reduce the activation energy for a particular reaction.
- They speed up the rate of reaction.
Example : Enzyme maltase converts maltose to glucose.

Catalytic action of enzymes :
- Mechanism of enzyme catalysis : Action of an enzyme on a substrate is known as lock-and-key mechanism.
- Accordingly, the enzyme has active site on its surface.
- A substrate molecule can attach to this active site only if it has the right size and shape.
- Once in the active site, the substrate is held in the correct orientation, enzymes provide functional group which will attack the substrate and forms the products of reaction.
- The products leave the active site and the enzyme is ready to act as catalyst again.

Enzyme catalysis
Industrial application of enzyme catalysis :
- Glucose Isomerase (enzyme) is used in conversion of glucose to sweet-tasting fructose.
- New antibiotics are manufactured using penicillin acylase (enzyme).
- Laundry detergents are manufactured using proteases (enzyme).
- Esters used in cosmetics are manufactured using genetically engineered enzyme.
Nucleic acids :
In living cells certain type of information is passed unchanged from one generation to the next. Such information is called genetic information and its transfer to new cells is accomplished by nucleic acids.
Nucleic acids : Nucleic acids are unbranched polymers of repeating monomers i.e. nucleotides. In other words, nucleic acids have a polynucleotide structure which in turn consists of a base, a pentose sugar and phosphate moiety.
Nucleic acids are bimolecules which are found in the nuclei of all living cells in the form of nucleo proteins or chromosomes.
(Nucleoproteins = Proteins + Nucleic acid)
(prosthetic group)
Types of nucleic acids : Ribonucleic acid (RNA) and deoxy ribonucleic acid (DNA). DNA molecules contain several million nucleotides while RNA molecules contain a few thousand nucleotides.
Chemical composition of nucleic acids :
Nucleic acids have a polynucleotide structure. Nucleic acids (RNA and DNA) consists of three components : (i) monosaccharide (sugar) (ii) nitrogen containing base and (iii) phosphate group.
(i) Monosaccharides : Nucleotides of both RNA consist of five membered monosaccharide ring (furanose) known as simply sugar component.

In RNA, the sugar component of nucleotide units is D—ribose and in DNA 2-deoxy—D-ribose. 2-deoxy means no—OH group at C2 position.
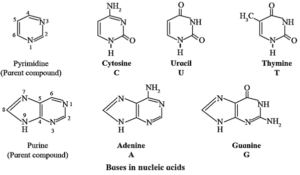
(ii) Nitrogen containing base : Total five nitrogen-containing bases are present in nucleic acids.
- Three bases with one ring (cytosine, uracil and thymine) are derived from the parent compound pyrimidine.
- Two bases with two rings (adenine and guanine) are derived from the parent compound purine.
- Each base in designated by a one-letter symbol. Uracil (U) occurs only in RNA while thymine (T) occurs only in DNA.
(iii) Phosphate group : The sugar units are joined to phosphate through C, and C, hydroxyl groups.
Nucleoside :
- A nucleoside contains two basic components of nucleic acids i.e. a pentose sugar and a nitrogenous base.

- A nucleoside is formed when 1—position of a pyrimidine (cytosine, thymine or uracil) or 9—position of guanine or adenine base is attached to C—1 of sugar by β-linkage.
Examples : Formation of nucleoside :

Nucleotides :
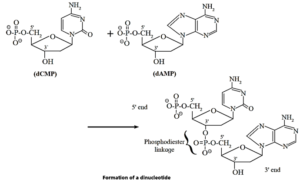
A nucleotide contains all three basic components of nucleic acids i.e., a pentose sugar, a phosphoric acid and a nitrogenous base.

These are obtained by esterification of C5—OH group of the pentose sugar by phosphoric acid. Nucleotides are joined together through phosphate ester linkage. Thus, nucleotides are monophosphates of nucleosides. Abridged names of some nucleotides are AMP, dAMP, UMP, dTMP and so on. Here, the first capital letter is derived from the corresponding base. MP stands for monophosphate. Small letter ‘d’ in the beginning indicates deoxyribose in uclectide the nucleotide.
Example :

Structure of nucleic acids :
- Nucleic acids, both DNA and RNA, are polymers of nucleotides, formed by joining the 3’ —OH group of one nucleotide with 5 —phosphate of another nucleotide. Two ends of polynucleotide chain are distinct from each other.
- One end having free phosphate group of 5’ position is called 5’ end. The other end is 3’ end and has free OH—group at 3' position.
Polynucleotide structure of nucleic acids : Schematic representations (a) and (b) :

Remember :
|
DNA double helix : James Watson and Francis Crick put forth in 1953 a double helix model for DNA structure.
Salient features of the Watson and Crick model of DNA are :
- DNA consists of two polynucleotide strands that wind into a right-handed double helix.
- The two strands run in opposite directions; one from the 5' end to the 3' end, while the other from the 3' end to the 5' end.
- The sugar- phosphate backbone lies on the outside of the helix and the bases lie on the inside, perpendicular to the axis of the helix.
- The double helix is stabilized by hydrogen bonding between the bases of the two DNA strands. This gives rise to a ladder like structure of DNA double helix.
- Adenine always forms two hydrogen bonds with thymine, and guanine forms three hydrogen bonds with cytosine. Thus A - T and C - G are complementary base pairs and the two strands of the double helix are complementary to each
Fig DNA double helix :

DNA double helix
Examples :
Sequence of the complementary strand of the following portion of a DNA molecule :
(i) 5' - ACGTAC-3'
The complementary strand runs in opposite direction from the 3' end to the 5' end. It has the base sequence decided by complementary base pairs A - T and C - G.

(ii) DNA molecule : 5-CGTTTAAG-3'
The complementary strand runs in opposite direction from the 3’ end to the 5’ end. It has the base sequence decided by complementary base pairs A-T and C-G.

We reply to valid query.